GBDT - XGBoost - LightGBM
一个很好的、对GBDT和XGBoost的介绍:XGBoost作者陈天奇的文章
1 简介
Gradient Boosting Decision Tree (GBDT)是一种常用来分类、回归的模型,而XGBoost与LightGBM是基于GBDT的两种实现。XGBoost与LightGBM都是被广泛使用的Github开源库,XGBoost在几年前帮助很多Kaggle队伍夺冠,从而名声大噪;而LightGBM作为新生事物,比XGBoost快很多倍,所以近期也越来越流行了。
Gradient Boosting Decision Tree从名称上来讲包含三个部分:Decision Tree、Boosting、Gradient Boosting。决策树我们都比较熟悉,在此略过不谈。Boosting这种方法,是指用一组弱分类器,得到一个性能比较好的分类器;这里用到的思路是给每个弱分类器的结果进行加权。Gradient Boosting是指使用gradient信息对分类器进行加权,之后的部分会详细介绍gradient加权的思路。
综上,GBDT是一种使用gradient作为信息,将不同的弱分类decision trees进行加权,从而获得较好性能的方法。

2 GBDT的一般步骤
Step 1: 初始化
初始化y_hat在第0时刻的值。
Step 2:求残差
通过类似梯度下降法的思路,每次y都向梯度下降的方向挪一小步。只是在GBDT,y挪的一小步并不是一个variable,而是一个function。
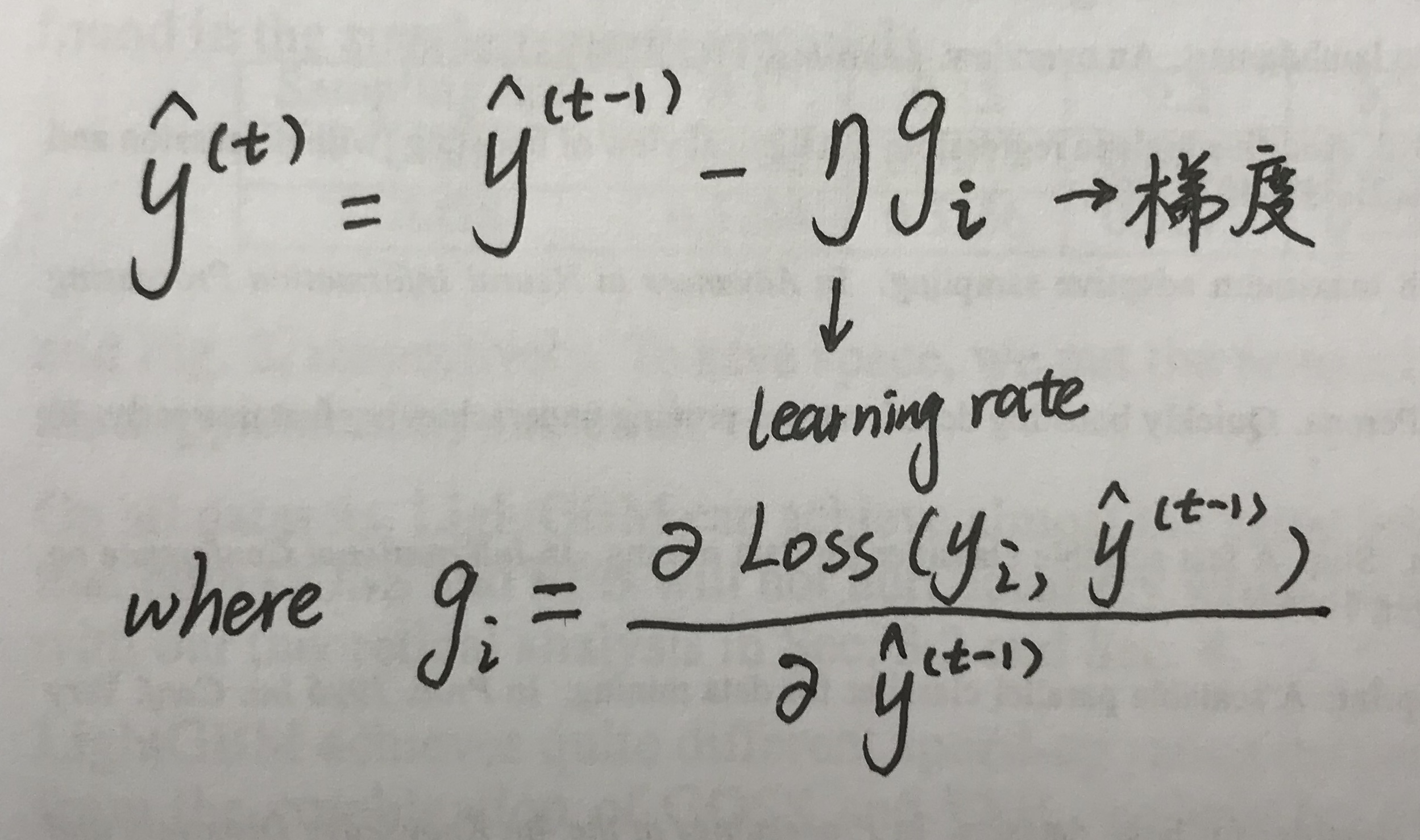
如果loss function是个square loss,那么g表示为:
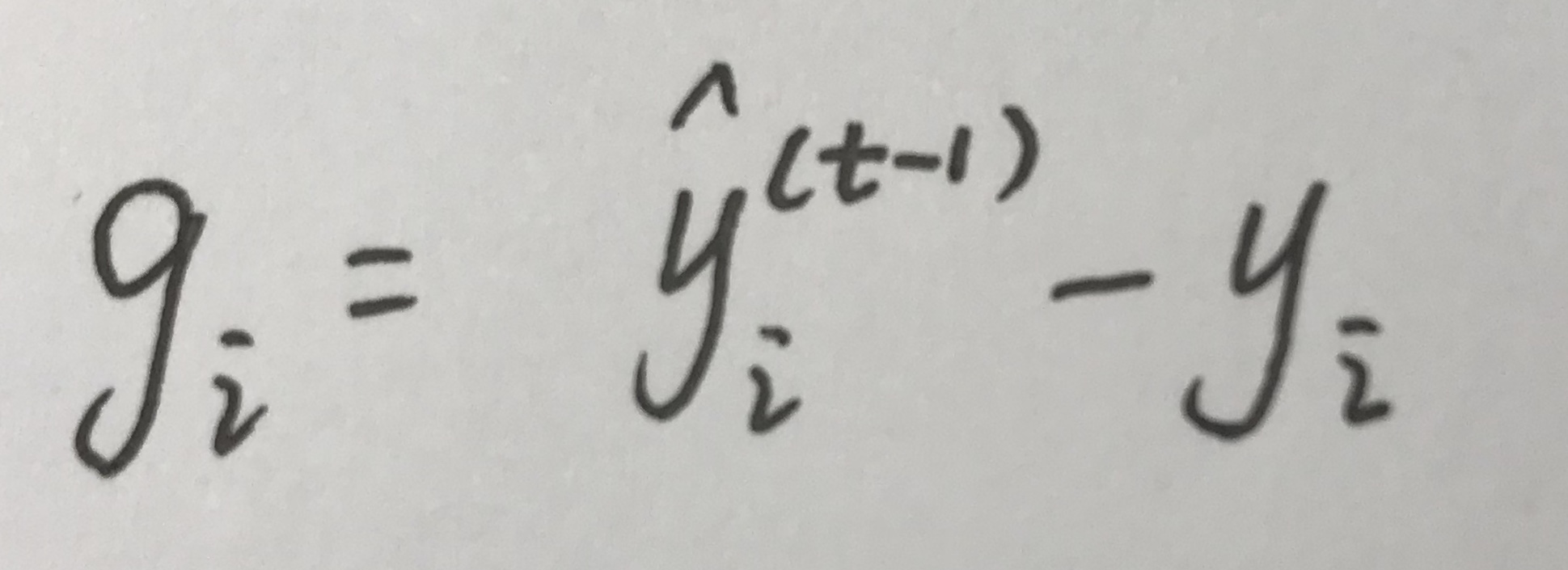
Step 3:构建决策树
使用决策树逼近这个残差 –g,得到第t个决策树:f_t。
Step 4:求叶节点权重

Step 5:更新输出y
y(t) = y(t - 1) + learning_rate * f_t
针对这个section讲的步骤,我做了一个简单实现。
3 XGBoost
在GBDT思想下,XGBoost对其中的步骤进行了具体实现。
变化1:提高了精度 - 对Loss的近似从一阶到二阶
传统GBDT只使用了一阶导数对loss进行近似,而XGBoost对Loss进行泰勒展开,取一阶导数和二阶导数。同时,XGBoost的Loss考虑了正则化项,包含了对复杂模型的惩罚,比如叶节点的个数、树的深度等等。
通过对Loss的推导,得到了构建树时不同树的score。具体score计算方法见论文Sec 2.2。
变化2:提高了效率 - 近似算法加快树的构建
XGBoost支持几种构建树的方法。
第一:使用贪心算法,分层添加decision tree的叶节点。对每个叶节点,对每个feature的所有instance值进行排序,得到所有可能的split。选择score最大的split,作为当前节点。
第二:使用quantile对每个feature的所有instance值进行分bin,将数据离散化。
第三:使用histogram对每个feature的所有instance值进行分bin,将数据离散化。
变化3:提高了效率 - 并行化与cache access
XGBoost在系统上设计了一些方便并行计算的数据存储方法,同时也对cache access进行了优化。这些设计使XGBoost的运算表现在传统GBDT系统上得到了很大提升。
4 LightGBM
LightGBM目前是XGBoost的有力竞争对手。就目前的一些report来说,LightGBM在更大、更sparse的数据上,比XGBoost的速度提升10倍有余;而它的精确度却没有很显著的损失。
变化1:让训练样本更少
因为GBDT可以看做对残差大的样本加权更大(因为下一个决策树是用来拟合上一个决策树之后的残差的),所以对残差小的样本,LightGBM认为它们对树的学习不是很重要,所以对这部分样本进行了采样。
变化2:让特征更少
因为很多数据集的feature是非常sparse的,所以会有很多互斥的features。互斥的features指两个features内积基本为0。
LightGBM将这些互斥的feature相加,得到了更少的feature bundles。得到最少feature bundles是一个np-hard的问题,LightGBM对这个问题也做了一些优化。
基于这两方面的improvements,LightGBM是目前来说表现最好的GBDT系统。
(完)